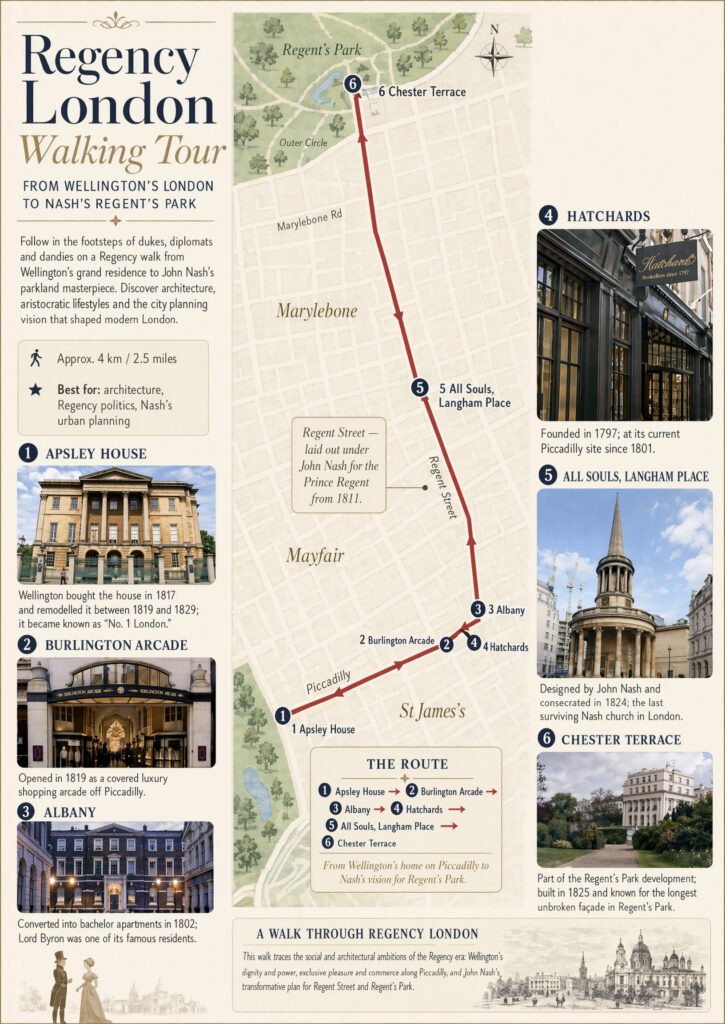
ChatGPT Images 2.0 is a new image generation model released by OpenAI. OpenAI introduced this model not merely as a simple image rendering tool, but as a model that elevates complex visual tasks to a level where they can be immediately applied in practice. As of the official announcement, it is available starting today in ChatGPT, Codex, and API.
The key change is precision. OpenAI explained that this model follows complex instructions better, positions objects and their relationships more accurately, and renders small text, icons, UI elements, and complex screen layouts more stably. They also emphasized its support for various aspect ratios.
Language processing has also been enhanced. It was stated that text rendering accuracy has improved not only in English but also in non-Latin-based languages such as Japanese, Korean, Chinese, Hindi, and Bengali. This explains that it makes work where the text itself becomes part of the design, such as posters, diagrams, and comics, more natural.
The range of stylistic expression has also expanded. It was stated that various visual languages, such as photographs, cinematic stills, pixel art, and comics, can be handled with greater consistency, and the completeness of textures, lighting, composition, and details has been improved. Therefore, it was introduced as being useful for game prototypes, storyboards, marketing creative, and the production of visuals for specific genres.
One of the biggest differences in this version is the addition of a thinking feature. OpenAI described Images 2.0 as its first “thinking” image model. By selecting the Thinking or Pro model, you can perform more complex tasks by utilizing web search to reflect the latest information, creating multiple images at once, and reviewing the results.
We have also expanded output versatility. Supporting various aspect ratios from 3:1 to 1:3, you can create content tailored to formats such as banners, slides, posters, mobile screens, bookmarks, and social images. The API also supports output at up to 2K resolution.
OpenAI is also tailoring this model for information visualization and practical production. They stated that it was designed to perform better in tasks where accuracy and structure are critical, such as explanatory graphics, educational materials, and visual summaries. Image generation features can be used within the Codex, and in the API gpt-image-2 It can be integrated into the product as a model.
However, limitations remain. OpenAI noted that errors can still occur in origami guides, puzzles like Rubik's Cubes, precise details of hidden or slanted faces, very dense and repetitive patterns, and diagrams requiring precise arrows and labels.