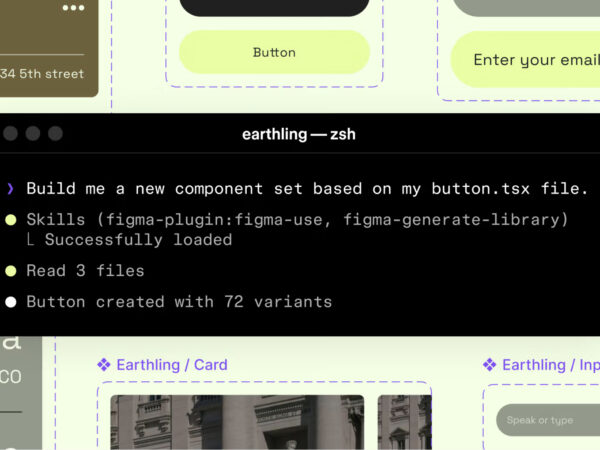
구글이 대규모 AI 제미나이를 공개했습니다. ChatGPT에 대응해 공개한 Bard가 부족한 성능으로 아쉬웠었는데 막강한 성능으로 돌아왔습니다. 구현에 집중하는 다른 AI와 다르게 ‘추론’에 있어 놀라운 경험을 공유했습니다.
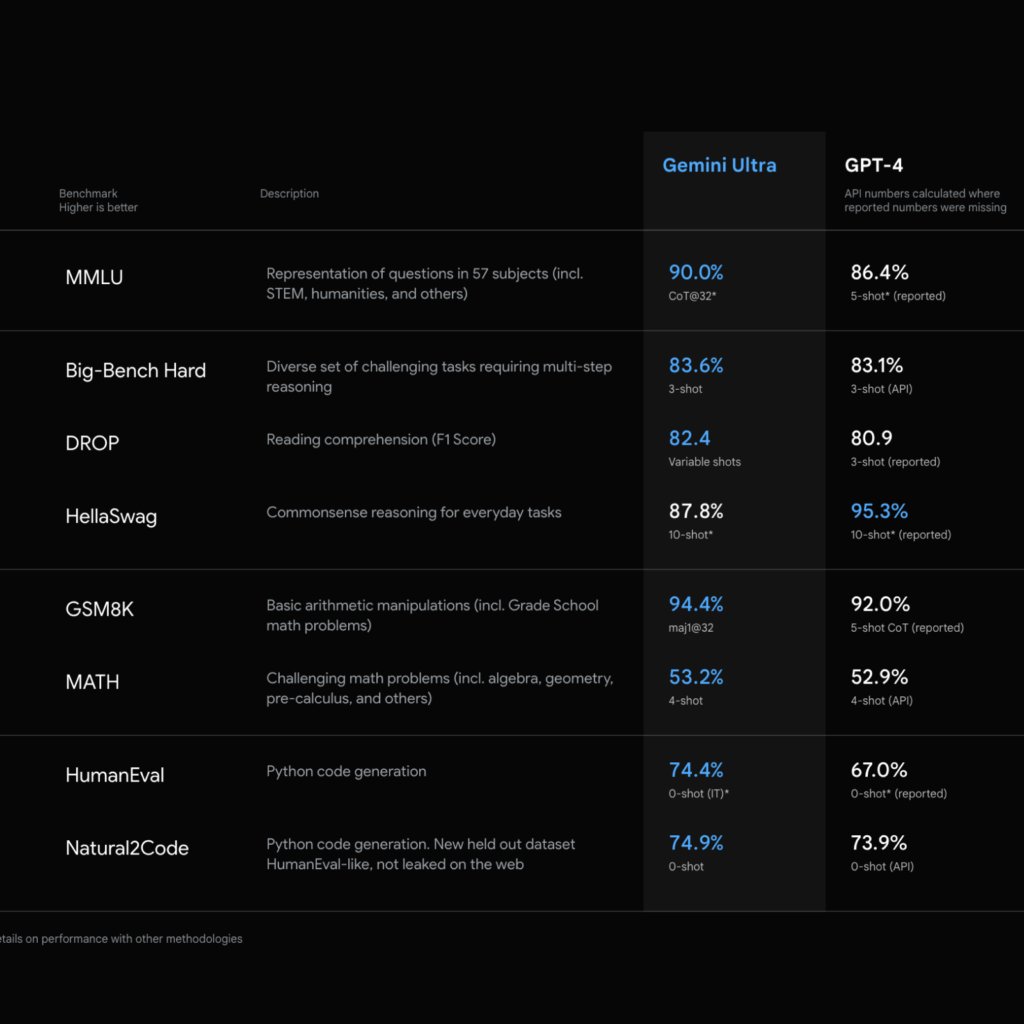
Gemini Ultra는 수학, 물리학, 역사, 볍, 의학, 윤리 등 57개 과목을 조합해 테스트하는 MMLU (Measuring Massive Multitask Language Understanding) 에서 90.0%의 점수를 받아 인간 전문가의 89.8%를 넘어섰습니다. 성능을 측정하는 벤치마킹이지만 놀라운 결과입니다.
Gemini는 텍스트와 이미지를 가리지 않습니다. 다양한 형태의 정보를 인지하고 추론할 수 있습니다. 사람이 추상적으로 의미를 약속해 사용하는 음표와 같은 정보도 해석할 수 있습니다. 말 그대로 Anything to Anything이 가능한 모델입니다.
구글이 공개한 예시 영상은 마치 영화 속에서만 보았던 AI 비서처럼 자연스럽습니다. 사람이 손으로 그린 그림을 마치 사람처럼 이해할 수 있고 소통하면서 더 복잡한 추론을 통해 결론을 내립니다. 여러 단서를 바탕으로 나라를 맞추는 게임에서는 세계 지도 위에 손가락으로 위치를 짚어도 어느 나라인지 이해합니다. 매트릭스의 한 장면을 사람이 따라하는 영상을 보고 어떤 영화를 따라했는지도 맞춥니다. 문화적 맥락을 알아야만 해석할 수 있는 복잡한 추론도 가능합니다.




사람처럼 이해하고 생각하는 것 뿐만 아니라 기계의 규칙을 정하는 것도 능합니다. 파이썬, 자바, C++와 같은 보편적인 프로그래밍 언어로 코드를 짤 수 있습니다. 코딩 성능을 측정하는 HumanEval 등의 벤치마크에서 탁월한 성능을 보여줍니다.

Gemini 1.0은 Gemini Ultra, Gemini Pro, Gemini Nano로 3개 모델을 제공합니다. 성능과 규모에 맞춰 제공될 예정이며 구글의 서비스와 제품에 적용될 예정입니다. Bard에는 Gemini Pro가 적용되며 픽셀 8 Pro에는 Gemini Nano가 적용됩니다. 12월 13일부터는 개발자와 기업 고객이 Gemini API로 Gemini Pro를 사용할 수 있다고 합니다.

이미지나 비디오를 해석하는 기능은 빠르게 정복될 것이라 생각했는데 추론 능력이 이렇게까지 빠르게 성장할 것이라곤 생각하지 못 했습니다. 사람이 오랜 시간 축적해야 해석할 수 있는 추론까지 해내는 영상이 놀라웠습니다.
아직은 실제로 서비스에 적용이 된 것을 보지 못 했기 때문에 더 지켜봐야 겠지만 표면적으로 보이는 형태로 해석하는 것을 넘어 그 속에 숨겨진 의미를 끄집어 내는 성능은 무지막지하게 좋아졌습니다. 이제 사람처럼 말로 대답하는 것을 넘어 시각적으로 대답하는 것 까지 발전한다면 디자인에도 커다란 혁명이 생길 것 같네요.